Docker Container 筆記
因為最近 Side Project 增加,常常都要一條龍而且環境也都不盡相同,決定花一點時間了解 Docker,結束原本都只會 docker compose up 的狀態。Docker 是一個基於 Container 的封裝環境工具,為什麼會需要這樣的工具?又為什麼會有 Docker 誕生,就要先來看看從以前到現在是怎麼去部署一個服務。
以下內容非常的長,如果只想要了解 Docker 怎麼操作可以從 Docker 第一步開始閱讀。
部署歷史
一開始部署服務只要有很多台電腦上面裝著 OS 執行我們寫好的服務即可,這種最陽春的作法叫做 Bare Metal,但面對軟體多變的需求,無論是可能需要彈性擴充硬體、調整韌體、系統是不是還安好,這一切可能就會需要一個團隊去進行維運,而進而變成只要有需要伺服器就得養一支團隊。
於是乎,因應 IaaS (Infrastructure as a Service) 需求 - 亦即一些維運相關的基礎建設服務 e.g. 網路、儲存等基礎資源平台誕生了,也就是我們現在耳熟能詳的 AWS, GCP … 等等,他們使用了 Virtual Machine 的技術,讓他們可以在一台電腦上安裝多個 OS,於是乎一台電腦上可以有不同的服務在跑而且不會互相影響,基於同一個硬體之上,也可以相對動態的去調整每一個服務的資源。
有了基礎的 IaaS 建設,應運而生的 PaaS (P for Platform) e.g. Log, DB, monitor … 與 SaaS (S for Software) e.g. 我們直接使用的 Web, App,這些服務呈現更爆炸性的成長,服務邏輯越發複雜、流量跟高併發的狀況也越來越多,開發者開始在架構層追求更可靠(Reliability)、可用(Availability)且穩定(Stability)的系統,所以嘗試將服務做到水平擴展,降低單點失效(Single Point Of Failure)的風險,並將服務從單體式(Monolithic)的拆解成微服務的型態更不容易互相影響。
微服務的趨勢
什麼是微服務?一個好的微服務會有什麼特色?
微服務是一種架構設計上的風格,這種風格希望將單體巨大的專案拆成可以被獨立部署的小專案,以一個電商的 API Server 來比喻,過去可能會員、商品、帳款所有的 API 都綁在一個 Server 上,並且寫成一大包的程式,但微服務鼓勵我們把會員、商品跟帳款的邏輯都分開,這樣開發會員系統的開發團隊可以選擇更適合的技術棧或語言來進行開發不會與其他服務互相依賴,並且也不會因為那一大包程式如果掛掉整個服務就掛掉,而是各自區塊獨立運行。
因應這樣的趨勢,有人提出了 12 factor app 的方針,從好的微服務方針,也可以更了解微服務應該是什麼樣子1:
- Codebase: One codebase per service, tracked in revision control.
- Dependencies: Explicitly declare and isolate dependencies
- Config: Store configuration in the environment
- Backing Services: Treat backing services as attached resources
- Build, Release, Run: Strictly separate build and run stages
- Processes: Execute the app in one or more stateless processes
- Data Isolation: Each service manages its own data
- Concurrency: Scale out via the process model
- Disposability: Maximize robustness with fast startup and graceful shutdown
- Dev/Prod Parity: Keep development, staging, and production as similar as possible
- Logs: Treat logs as event streams
- Admin Processes: Run admin and management tasks as one‑off processes
以上不一一的解釋,但舉例來說:今天一般在開發上常見會基於一個 Repo 去維護並且不會有不同包程式碼在 Server 上;讓依賴關係可以清楚地表達出來 e.g. Docker 的 Dockerfile, NPM 的 package.json;Config 則放在環境之中 e.g. 前端常常會遇到的 .env 檔案 … 等等。
在這樣的主張下,Container 這門技術特性與微服務不謀而合。
Container
Container 有別於 VM 是基於 OS 之上的一個執行環境,透過下面 Linux 內建已久的三個功能,讓我們可以在 OS 之上還能運行一個隔離的環境2:
- chroot: 讓目錄不會相互影響
- namespace: 讓 Process 不會相互影響
- cggroup: 為不同的隔離環境做資源調度
這三件事怎麼做到呢?以下範例微調自 Front End Master,我們可以在 Docker 的環境裡面嘗試一下(為了不要把自己的電腦弄壞 XD),可以透過以下指令在 Docker 裡面起一個最簡單的 ubuntu 環境:
$ docker run -it --name docker-host --rm --privileged ubuntu:bionic這時候我們可以在 docker dashboard 或是透過 docker container list 看到我們目前已經成功起了一個 docker-host 的服務。
關於詳細指令的內容會在後續進行介紹,但這邊快速的帶過這一行指令,就是指讓 docker 針對 image ubuntu bionic 版本來起一個 container,並且因為 -it 進入 stdin 模式,可以想像就是我們進入該 container 的 terminal 進行操作。另外 --rm 則是當你離開的時候會自動移除、 --privileged 則是開啟 Docker 的安全限制,讓我們可以執行更底層的一些 API 權限。
chroot (Change Root)
首先我們可以在根目錄開一個新的 root 資料夾,並對個資料夾使用 chroot 指令,指定在更換根目錄之後使用 bash 作為 shell:
$ cd /
$ mkdir new-root
$ cd new-root
$ chroot . bash接著我們會發現因為 new-root 沒有 bash 的檔案所以要做一些調整,將檔案本身跟相依的檔案複製進 new-root 資料夾之中。
$ mkdir /new-root/bin
$ cp /bin/bash /bin/ls /new-root/bin/
linux-vdso.so.1 (0x00007fff06791000)
libtinfo.so.5 => /lib/x86_64-linux-gnu/libtinfo.so.5 (0x00007f19d5c20000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f19d5a1c000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f19d562b000)
/lib64/ld-linux-x86-64.so.2 (0x00007f19d6164000)
# 列出 bash 跟 ls 指令的資料庫依賴關係
$ ldd /bin/bash
$ mkdir mkdir /new-root/lib{,64}
$ cp /lib/x86_64-linux-gnu/libtinfo.so.5 /lib/x86_64-linux-gnu/libdl.so.2 /lib/x86_64-linux-gnu/libc.so.6 /new-root/lib
$ cp /lib64/ld-linux-x86-64.so.2 /new-root/lib64
$ ldd /bin/ls
$ cp /lib/x86_64-linux-gnu/libselinux.so.1 /lib/x86_64-linux-gnu/libpcre.so.3 /lib/x86_64-linux-gnu/libpthread.so.0 /new-root/lib當檔案都處理完成,我們再執行一次 chroot . bash 會發現根目錄已經變為 new-root 了。所以透過 Unix 提供的 chroot 指令,讓我們可以控制 Container 不對外部的檔案進行操作。
Namespace
但檔案是隔離開來了,Process 沒有,當我們嘗試在開一個虛擬 terminal 來連入 Docker 的時候,我們可以做一個測試來看是不是 chroot 的操作可以改變到原先環境的 Process :
在另外開的一個 docker-host terminal 裡面執行一個背景程式:
# 列印出文件最後一行 -f 持續印出 & 背景執行
$ tail -f /new-root/secret.txt &
[1] 78
$ ps
PID TTY TIME CMD
66 pts/1 00:00:00 bash
78 pts/1 00:00:00 tail
79 pts/1 00:00:00 ps我們會發現我們執行了一個 id 為 78 的 Background Process,接著到第一個 chroot 後的 terminal 中,刪除 id 78 的 Process。
$ kill 78這時候回到第二個 terminal ps 的時候發現 id 78 的 Process 消失了,這代表只有 chroot 是不夠的,我們還需要做到 Process 的隔離,這邊會需要使用 unshare 這個指令。
所以為了能使用這個指令,剛剛 chroot 的時候我們也注意到了,如果要將一個指令移到對應的根目錄,我們必須將關聯的檔案也一併移入這樣太複雜了,所以這邊我們載入一個現成系統到新的根目錄,概念類似於再安裝一個 OS 到此目錄,而這邊使用 Debian 的 debootstrap 來安裝。
$ apt-get update
$ apt-get install debootstrap
$ debootstrap --variant=min --variant=minbase bionic /new-root安裝後,我們使用 unshare 指令,分別對 uts、ipc、pid、mount、 user 等 Namespace 的隔離,而這邊 Namespace 在 Linux Manual 裡面的定義2:
A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
簡言之 Namespace 是 Linux 實作的一個隔離機制,可以將資源放在不同 Namespace 之中,而裡面的程式就可以有獨立的系統資源,其中 Linux 有提供的資源隔離有六種:
- uts: 網域跟主機名
- ipc: 跨 Process 的溝通
- pid: Process Id
- mount: 文件系統掛載點,由於 Linux 的檔案系統都需要被連結到目錄樹才能使用,所以我們現在開了一個新的空間點,要掛載到對應的資料夾作為掛載點。3
- User: 隔离用户和用户组的ID
- Network: 網路資源
所以這邊我們對資源進行隔離:
$ unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot /new-root bash
$ mount -t proc proc /proc
$ mount -t sysfs sys /sys
$ mount -t tmpfs tmp /tmp並同時使用 --fork 讓特定的程式可以直接創立新的 Process 並將原本的資訊都先複製進去跟 --map-root-user 切換回原本的使用者。
最後使用 mount 完成檔案掛載,這邊 -t 就是檔案的格式,根據檔案系統格式為 proc (process), sysfs (system file systen), tmpfs (temporary file system) 然後來源為 none 對應到目標為下面三個檔案夾。
接著我們在進行一次測試就可以發現我們的隔離空間看不見外面的 process 了,從以上我們可以發現,其實透過這些技術隔離出來的空間也只是一系列的獨立的 Process,只是從內部看不到外部而已。
CGGroup (Control Group)
當可以創建隔離環境之後,最後就是調度主機上的資源,以下的操作將從現成的 cgroup-tool4 工具來操作跟模擬:
# 1 root
$ apt-get install -y cgroup-tools htop
$ cgcreate -g cpu,memory,blkio,devices,freezer:/sandbox
$ unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot /new-root bash
# 2
$ ps aux
$ cgclassify -g cpu,memory,blkio,devices,freezer:sandbox <unshare bash pid>
# check if cgclassify success
$ cat /sys/fs/cgroup/cpu/sandbox/tasks
$ cat /sys/fs/cgroup/cpu/sandbox/cpu.shares
$ cgset -r cpu.cfs_period_us=100000 -r cpu.cfs_quota_us=$[ 5000 * $(getconf _NPROCESSORS_ONLN) ] sandbox
$ cgset -r memory.limit_in_bytes=80M sandbox
$ cgget -r memory.stat sandbox
$ htop
# 1
$ yes > /dev/null 以上操作透過創造 sandbox 群組後,定義在該 namespace 之下的特定 process 只能使用多少資源,接著透過 htop 來確認。
什麼是 Docker ?
有了這樣隔離的技術,Docker 實作出讓 Container 執行的中間集成環境,除了封裝複雜的隔離步驟外,另外也做了容量上的優化5,打造輕量的容器引擎。
基於這之上推出部署工具 Docker Machine 以及不同 Container 之間溝通安排的 Docker Swarm 及對應管理的 Docker Compose,這些目前都被直接整併進 Docker 核心之中,而 Docker 還營運 Docker Hub 跟陸陸續續出了相關的部署服務,推廣出了現在以 Container 為主要部署環境的生態。
聽起來 Container 相當美好,但 Container 也有缺點 6,從以上三個核心不難發現 Docker 是建立在 Linux 系統上的機制,必須共享類似的 Kernel 才能進行。如果今天底層的 OS 沒有這些功能自然就得透過不同的實作機制,這也是為什麼那麼多年後 Docker 才推出 Windows 版本。另外難道 Container 就不可能跳脫出 Container 環境嗎?Container 與 VM 隔離的程度不同,這邊可以參考這篇文章,討論 Container 可能會共享了什麼7。
Docker 架構
以上初步了解了 Docker 誕生的背景以及 Container 核心,接下來可以來了解一下 Docker 的基本架構,從 Docker 的架構圖8不難發現 Docker 分成幾個部分:
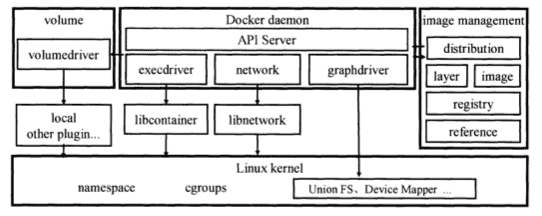
- Client: 使用者互動下指令的部分 e.g. 我們在 terminal 下 docker run
- Registry: 存放 Docket Image 的地方,類似 Github 存放 Repo 的概念,官方有開放的 Docker Hub 作為公開的 Regitry。
Docker Daemon
而上面我們可以發現最核心的就是 Docker Daemon,根據 Docker 容器與容器雲這本書介紹 5,Docker Daemon 是一個收發 Client 端 Request 並管理 Docker 物件,像是:Images, Containers 等地方。作為前端來想像 Docker Daemon 不妨當成類似伺服器的概念,而不同的 Docker Daemon 也可以互相溝通(所以才構成 Docker Compose 使用狀況)。
- Images: 是一個讓我們用來製造 Container 的模板,是基於 Union FS 以分層方式紀錄每一次檔案系統的操作,即便如此因為包含整個完整的文件系統,所以體積非常大,類似建築設計圖與建築材料一般的存在。
- Containers:是 Image 實際產生出來的環境實例(Instance)且核心是 Process,今天 Container 主 Process 結束,Container 就結束了。我們可以使用 Docker API, CLI 來控制,類似實際蓋出的建築。
- Volumes: 是我們檔案放在 Container 讀寫層的方式,可以保留在 Container 生命週期之後
- Networks: 是我們 Docker 創建出來的主機位置,可以讓 Container 互相溝通。
那 Docker 是怎麼處理這些 Request 並透過管理這些物件呢?以下會從自己比較熟悉的東西去類比相應的 Driver,但不代表運作原理雷同或實現方式一致,只是從前端開發者來看類似這樣的工具。
- Volume Driver: 負責外部檔案掛載的功能,類似我們剛剛實作的 mount 動作。
- Exec Driver: 負責剛剛上述提到的 namespace 的建立跟資源調度處理,以及與 Container 內部的溝通。
- Network Driver: 負責 Continer 的網路環境設置 e.g. 防火牆、Port 跟 IP 分配等等,類似 Apache 的存在。
- Graph Driver: 負責處理 Image 版本跟連動關係紀錄,類似 npm 的存在。
以上大概知道了 Docker 有哪些東西,接下來我們可以深入各個 Docker Object 究竟是怎麼運作。
小結
目前學 Docker 覺得最大的好處就是私底下要學新技術的門檻變低了,過去想摸 Hasura、Redis … 可能光是查 AWS 服務就要老半天,現在可以透過 Docker Container 在自己的電腦上輕易接觸到這些技術,而透過別人的 Dockerfile 像是 Volume 或是 RUN command 也能了解工具的檔案結構跟需要設定的參數。
參考資料
- 🐋 Learn Docker and Containers in the Complete Intro to Containers course! Create deploy and dev environments, and coordinate large scale applications.Docker
- 容器與容器雲(第2版) | 天瓏網路書店